MARTIJN PANTLIN
Some notes from herri’s full stack web developer on the AI phenomenon
On Jan 9 2023, at 5:54 pm, martijn wrote:
I didn’t have time to play around yet, but I want to test out some form of integration with the chatGPT API and herri. There are already 2 interesting browser extensions I found using chatGTP:
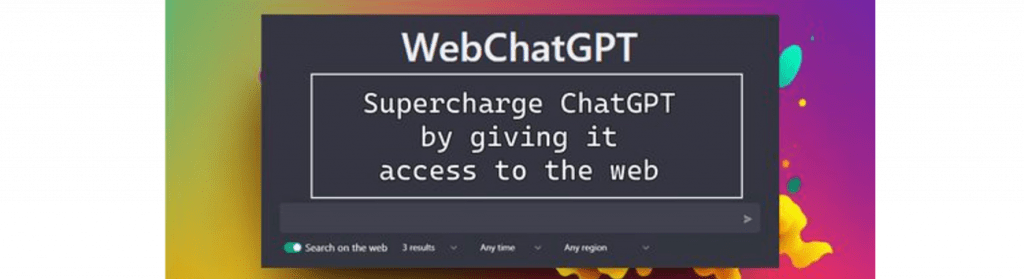
This one can use the web to augment its results. Currently chatGTP is based on a static database from years up to 2021. So newer information on the net is not indexed and used by the bot. This plugin tries to pull in current data from the web to make better time sensitive responses.
Merlin openai chatgpt (might not be available on Firefox yet)
The bot can respond to anything you select in a website, summarize a piece of text, explain a concept further, looks for a solution on a question, etc.
Here’s how it works:
➡️ Simply select any online content
➡️ Click on Cmd+M (Mac) or Ctrl+M (Windows) to open Merlin box
➡️ Choose what you want to do with it (create a reply, summarize, make it shorter, or add some fun)
➡️ And voila! You’ll get an 80% done reply at your fingertips
But it’s too early. The servers of chatGPT are completely overloaded and they keep changing ways to access it. It will be behind a paywall soon. Many companies are being built on top already, and they will charge for their services. Trained AI bots will get so incredibly valuable over time, finally people will begin to understand the impact of giving all of their data for free to a few giants, exploiting and censoring it they way they see fit to make gains. We are at the mercy of our own output and it will come back to haunt us in spectacular ways.
JURGEN MEEKEL: This is great Martijn, I tried Merlin in Chrome and it works well… and is still for free. How long will it take for Merlin AI to become a paid feature?
soon.
it takes energy to run those servers, energy needs to be paid by someone, preferably the user. part of the API will probably remain free in order to gain more usage data and train the bot via iteration and self learning to constantly improve output, aka satisfy the user more.
unless politics derive consensus about financing ‘free public bots for the good of humanity’ via subsidies or other means, smart AI will not be accessible for the ‘poor’, hence only enlarging the gap between classes. government sponsored bots are susceptible to corruption and censorship, and also don’t feel like the best solution.
fast access to data has always been monetized, far before the digital age.
the term ‘Open AI’ is nice, but who is sponsoring this venture?
who’s in control of the data feeds and filters?
blockchain promises to ‘solve’ this dilemma, by offering decentralized AI that is open source and managed by a ‘democratic’ DAO. SingularityNET is a project combining artificial intelligence and blockchain to democratize access to artificial intelligence.
it’s run by a well known AI researcher.
Ocean Protocol offers a decentralized marketplace for data sets. this enables anyone to purchase this data for training purposes. the data is encrypted, so it cannot be copied or extracted by the licenser, only used for computations.
as long as the data sets are from a ‘true’ source and raw, various parties could train various bots on the same data, creating ‘personality’ in bots, like left- or right-wing oriented.
so my current conclusion: nothing changes, just everything is being digitized, in which there might be no limits.
apple will launch its first AR glasses this year, which could mark an ‘iphone like’ singularity in the normalization of ‘augmented reality’, by your own set variables. your living room could become a permanent tropical aquarium and your friends all frog-like. real time stable diffusion will be able to feed you any audio visual experience you can dream of (censored of course, just not on the dark web).
this is the matrix.
and thus we dream on…
i wish future generations good luck, they will adapt and be alright.
again, nothing changes, just our perception.
i’m happy to have contributed to this data in a hopefully meaningful way, by responding to forum questions and asking questions that were answered.
that’s a counter argument against my credo ‘my data is my data’, in which i explore the possibilities of not sharing data publicly. one could argue that by not ‘participating’ in the creation of data that can be mined, one’s values, patterns and preferences are not included into the model.
kinda like a digitized version of not having kids and ‘training them’ with your belief systems.
as we all know, kids will change and adopt their own belief system by self learning, hence ‘self learning AI’.
for now this saves me a minute of development time and some biological memory usage:
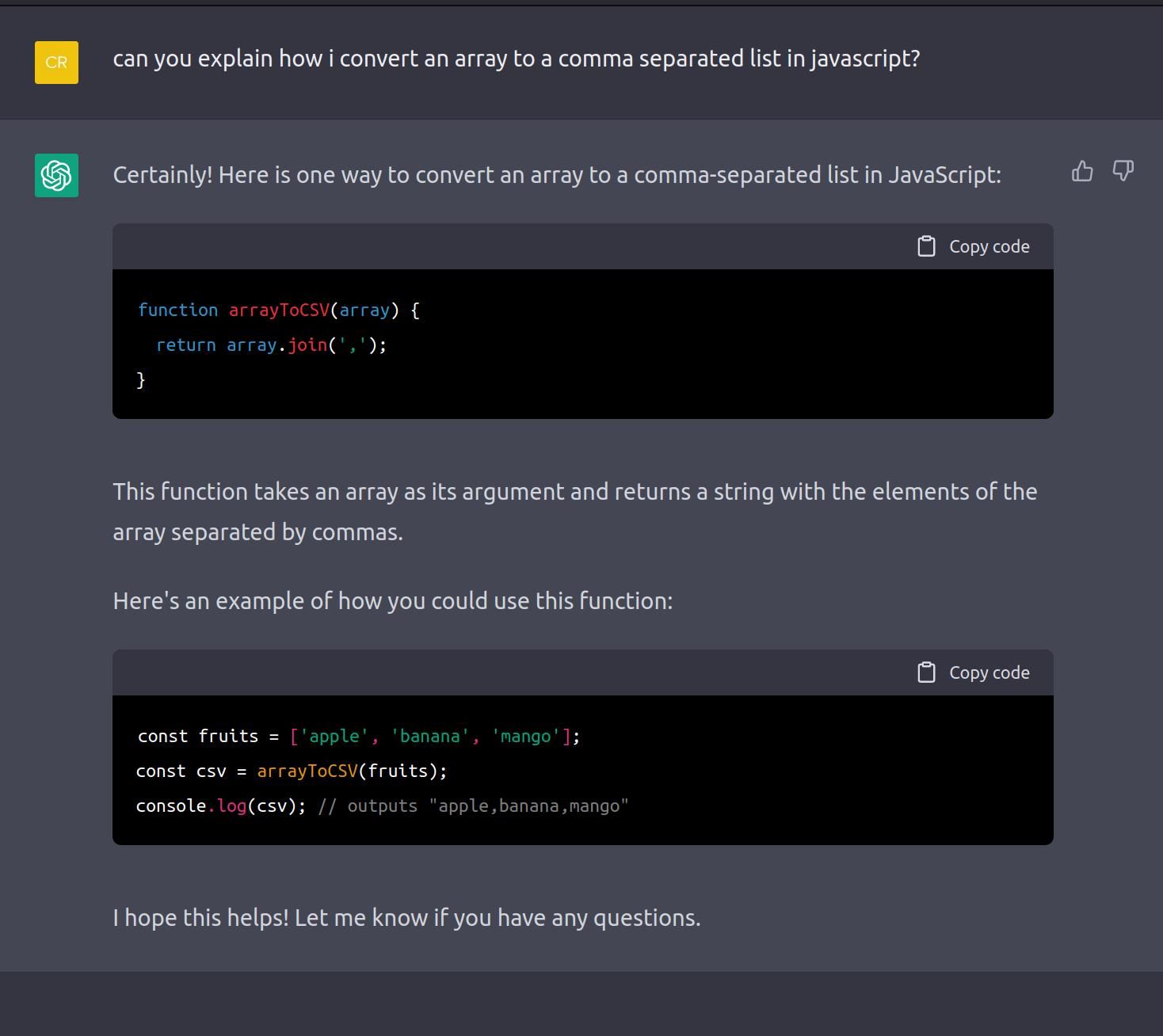
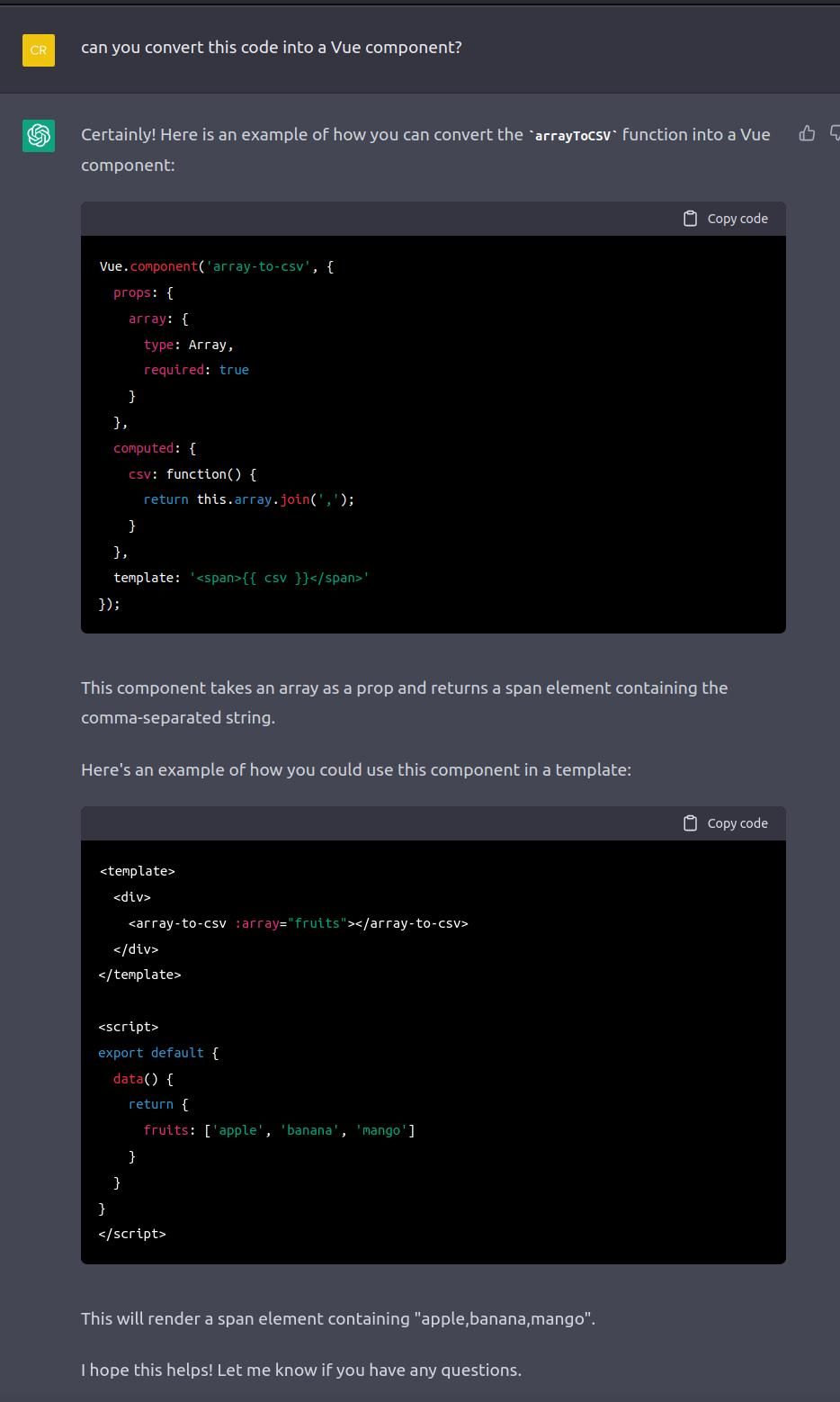
“The nothingness of digital code may shape the individual’s inner life and exclude the human from processes of self-knowledge. Indeed, humans currently do not possess a mode of access to the apparatus any more than they have insight into a mind-independent reality.”
Andrew C. Wenaus
Literature of Exclusion: Dada, Data and the Threshold of Electronic Literature